1,进口和eda
import os iskaggle = os.environ.get('kaggle_kernel_run_type', '') from pathlib import path if iskaggle: path = path('/kaggle/input/us-patent-phrase-to-phrase-matching')
登录后复制
import pandas as pd df = pd.read_csv(path/'train.csv') df['input'] = 'text1: ' + df.context + '; text2: ' + df.target + '; anc1: ' + df.anchor df.input.head()
登录后复制
2,令牌化
from datasets import dataset, datasetdict ds = dataset.from_pandas(df) import warnings,logging,torch warnings.simplefilter('ignore') logging.disable(logging.warning) model_nm = 'anferico/bert-for-patents' # load model directly from transformers import automodelforsequenceclassification, autotokenizer model = automodelforsequenceclassification.from_pretrained(model_nm, num_labels=1) tokenizer = autotokenizer.from_pretrained('anferico/bert-for-patents')
登录后复制
def tok_func(x): return tokenizer(x['input']) # tokenize all the sentences using the tokenizer tok_ds = ds.map(tok_func, batched=true) tok_ds = tok_ds.rename_columns({'score':'labels'})
登录后复制
3,测试和验证集
eval_df = pd.read_csv(path/'test.csv') dds = tok_ds.train_test_split(0.25, seed=42) eval_df['input'] = 'text1: ' + eval_df.context + '; text2: ' + eval_df.target + '; anc1: ' + eval_df.anchor eval_ds = dataset.from_pandas(eval_df).map(tok_func, batched=true)
登录后复制
4,指标和相关性
import numpy as np def corr(x,y): ## change the 2-d array into 1-d array return np.corrcoef(x.flatten(), y)[0,1] def corr_d(eval_pred): return {'pearson': corr(*eval_pred)}
登录后复制
5,训练我们的模型
14625233945
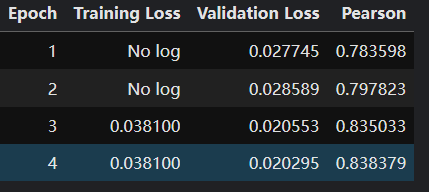
6,在测试集中获取预测
preds = trainer.predict(eval_ds).predictions.astype(float) preds = np.clip(preds, 0, 1) import datasets submission = datasets.Dataset.from_dict({ 'id': eval_ds['id'], 'score': preds }) submission.to_csv('submission.csv', index=False)
登录后复制
以上就是使用BERT在Kaggle上使用NLP入门的详细内容,更多请关注php中文网其它相关文章!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

