本文介绍了如何优化中json扁平化库的性能。该库用于在事件过滤引擎中匹配事件有效负载和过滤器。最初的实现使用递归深度优先搜索(dfs),导致高内存和cpu消耗,尤其是在处理大型有效负载时。
问题背景:
车队最初使用MongoDB作为主要数据存储,但随着数据复杂性的增加,迁移到PostgreSQL成为更优的选择。 然而,这引入了在Go中实现MongoDB原生查询功能的需求,因为没有现成的库可用。 事件过滤引擎需要将事件有效负载扁平化,然后与预先扁平化的过滤器进行比较。
初始实现的缺陷:
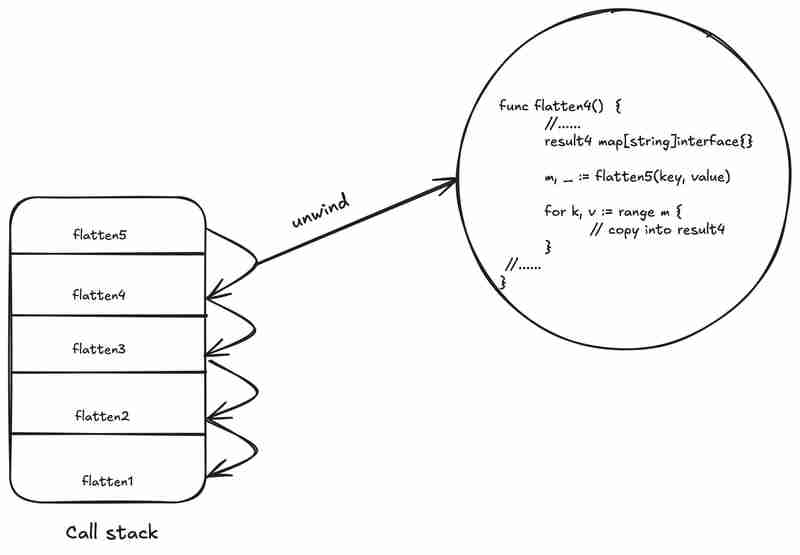
最初的递归DFS实现存在以下问题:
- 堆内存分配: 递归调用导致大量堆栈空间消耗,并进一步加剧了堆内存分配。
- 新的键字符串串联: 重复使用fmt.Sprintf进行键字符串拼接,效率低下。
- 结果映射复制: 递归返回时,结果映射会多次复制。
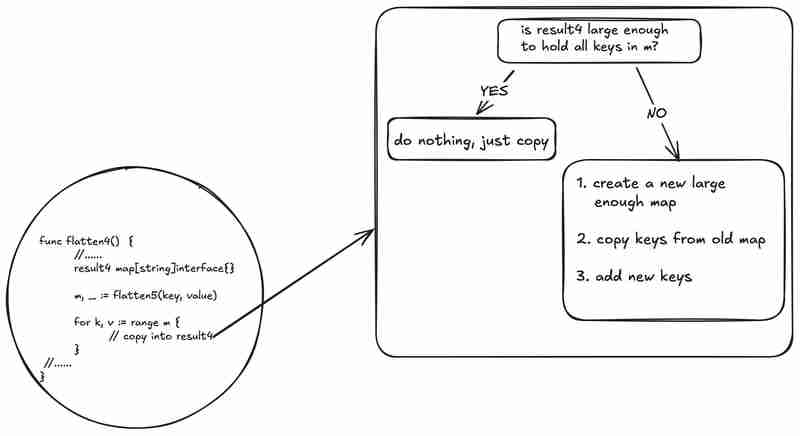
- 结果映射调整大小: 由于未预先分配足够的空间,结果映射需要多次调整大小,这是一个代价高昂的操作。
优化方案:
为了解决这些问题,作者改用迭代方法,使用自定义堆栈来跟踪JSON映射条目。 这避免了递归调用带来的堆内存分配和结果映射复制问题。 此外,使用字符串构建器高效地生成键,并通过countKeys函数预先计算结果映射所需的大小,从而避免了多次调整大小。
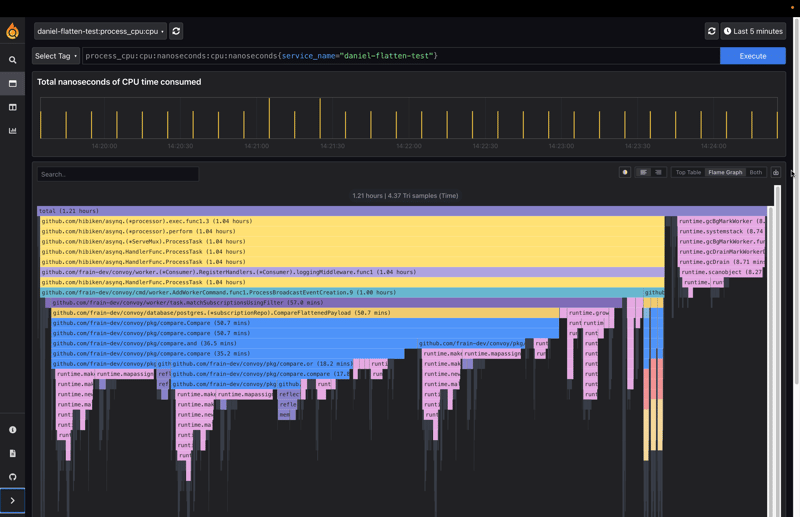
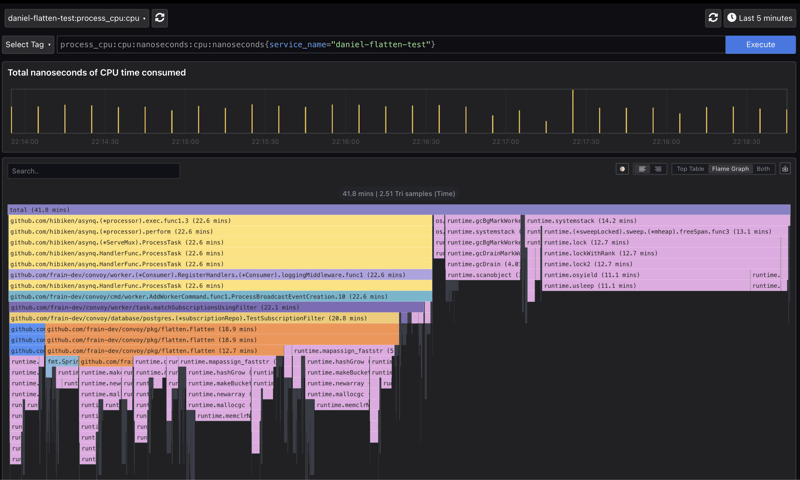
性能提升:
新的迭代实现将CPU时间和内存分配的性能提升了近70%。
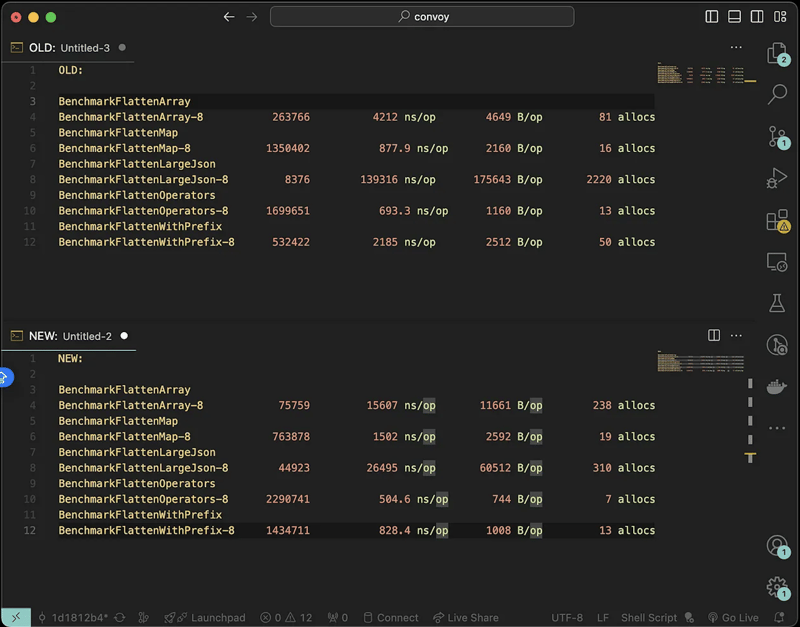
结论:
最初的递归实现虽然适用于小型有效负载,但在处理大型JSON数据时效率低下。 通过采用迭代方法并进行相应的优化,显著提高了扁平化库的性能,解决了生产环境中的瓶颈问题。 (注:图片略模糊,建议参考原文链接查看清晰版本。)
以上就是优化车队的扁平套件的详细内容,更多请关注php中文网其它相关文章!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

